Instituto Tecnológico de Matamoros
Unidad 1: Introducción al lenguaje ensamblador
Materia: Lenguajes de Interfaz
Alumno: José Juan Muñiz Hernandez
1.1 Importancia de la programación en lenguaje ensamblador.
La importancia del lenguaje ensamblador es principalmente que se trabaja directamente con el microprocesador; por lo cual se debe de conocer el funcionamiento interno de este, tiene la ventaja de que en él se puede realizar cualquier tipo de programas que en los lenguajes de alto nivel no lo pueden realizar. Otro punto sería que los programas en ensamblador ocupan menos espacio en memoria.
Puntos importantes:
- El único lenguaje que entienden los microcontroladores es el código máquina formado por ceros y unos del sistema binario.
- El lenguaje ensamblador expresa las instrucciones de una forma más natural al hombre a la vez que muy cercana al microcontrolador, ya que cada una de esas instrucciones se corresponde con otra en código máquina.
- El lenguaje ensamblador trabaja con nemónicos, que son grupos de caracteres alfanuméricos que simbolizan las órdenes o tareas a realizar.
- La traducción de los nemónicos a código máquina entendible por el microcontrolador la lleva a cabo un programa ensamblador.
- El programa escrito en lenguaje ensamblador se denomina código fuente (*.asm). El programa ensamblador proporciona a partir de este fichero el correspondiente código máquina, que suele tener la extensión *.hex.
Ventajas:
- Como trabaja directamente con el microprocesador al ejecutar un programa, pues como este lenguaje es el mas cercano a la máquina la computadora lo procesa mas rápido.
- Eficiencia de tamaño: un programa en ensamblador no ocupa mucho espacio en memoria porque no tiene que cargan librerías y demás como son los lenguajes de alto nivel
- Flexibilidad: Es flexible porque todo lo que puede hacerse con una máquina, puede hacerse en el lenguaje ensamblador de esta máquina; los lenguajes de alto nivel tienen en una u otra forma limitantes para explotar al máximo los recursos de la máquina. O sea que en lenguaje ensamblador se pueden hacer tareas especificas que en un lenguaje de alto nivel no se pueden llevar acabo porque tienen ciertas limitantes que no se lo permite.
Desventajas:
- Tiempo de programación: Como es un lenguaje de bajo nivel requiere más instrucciones para realizar el mismo proceso, en comparación con un lenguaje de alto nivel. Por otro lado, requiere de más cuidado por parte del programador, pues es propenso a que los errores de lógica se reflejen más fuertemente en la ejecución.
- Programas fuente grandes: Por las mismas razones que aumenta el tiempo, crecen los programas fuentes; simplemente requerimos más instrucciones primitivas para describir procesos equivalentes. Esto es una desventaja porque dificulta el mantenimiento de los programas, y nuevamente reduce la productividad de los programadores.
- Peligro de afectar recursos inesperadamente: Que todo error que podamos cometer, o todo riesgo que podamos tener, podemos afectar los recursos de la maquina, programar en este lenguaje lo más común que pueda pasar es que la máquina se bloquee o se reinicialize. Porque con este lenguaje es perfectamente posible (y sencillo) realizar secuencias de instrucciones inválidas, que normalmente no aparecen al usar un lenguaje de alto nivel.
- Falta de portabilidad: Porque para cada máquina existe un lenguaje ensamblador; por ello, evidentemente no es una selección apropiada de lenguaje cuando deseamos codificar en una máquina y luego llevar los programas a otros sistemas operativos o modelos de computadoras.
1.2 El procesador y sus registros internos
Definición: El procesador es el que se refiere a los diferentes tipos de artículos de sistemas informativos que forma parte de un microprocesador que es parte de un CPU o micro que es el cerebro de la computadora y de todos los procesos informativos desde los más sencillos hasta los más complejos.
Los registros del procesador se emplean para controlar instrucciones en ejecución, manejar direccionamiento de memoria y proporcionar capacidad aritmética. Los registros son direccionables por medio de un nombre.
Tipos de registros:
- Registros de segmento.
- Registros de propósito general.
- Registros de apuntadores.
- Registros de banderas.
- Registros de Pila.
- Registros Indice.
◘ Registros de segmento: Un registro de segmento tiene 16 bits de longitud y facilita un área de memoria para direccionamiento conocida como el segmento actual.
- Registro CS: El DOS almacena la dirección inicial del segmento de código de un programa en el registro CS. Esta dirección de segmento, mas un valor de desplazamiento en el registro apuntador de instrucción (IP), indica la dirección de una instrucción que es buscada para su ejecución.
- Registro DS: La dirección inicial de un segmento de datos de programa es almacenada en el registro DS. En términos sencillos, esta dirección, mas un valor de desplazamiento en una instrucción, genera una referencia a la localidad de un byte especifico en el segmento de datos.
- Registro SS: El registro SS permite la colocación en memoria de una pila, para almacenamiento temporal de direcciones y datos. El DOS almacena la dirección de inicio del segmento de pila de un programa en le registro SS. Esta dirección de segmento, mas un valor de desplazamiento en el registro del apuntador de pila (SP), indica la palabra actual en la pila que esta siendo direccionada.
- Registros ES: Algunas operaciones con cadenas de caracteres (datos de caracteres) utilizan el registro extra de segmento para manejar el direccionamiento de memoria. En este contexto, el registro ES esta asociado con el registro DI (índice). Un programa que requiere el uso del registro ES puede inicializarlo con una dirección de segmento apropiada.
- Registros FS y GS: Son registros extra de segmento en los procesadores 80386 y posteriores.
◘ Registros de propósito general: Los registros de propósito general AX, BX, CX y DX son los caballos de batalla del sistema. Son únicos en el sentido de que se puede direccionarlos como una palabra o como una parte de un byte. El ultimo byte de la izquierda es la parte “alta”, y el ultimo byte de la derecha es la parte “baja”. Por ejemplo, el registro CX consta de una parte CH (alta) y una parte Cl (baja), y usted puede referirse a cualquier parte por su nombre.
- Registro AX: El registro AX, el acumulador principal, es utilizado para operaciones que implican entrada/salida y la mayor parte de la aritmética. Por ejemplo, las instrucciones para multiplicar, dividir y traducir suponen el uso del AX. También, algunas operaciones generan código mas eficiente si se refieren al AX en lugar de a los otros registros.
- Registro BX: El BX es conocido como el registro base ya que es el único registro de propósito general que puede ser índice para direccionamiento indexado. También es común emplear el BX para cálculos.
- Registro DX: Es conocido como el registro de datos. Algunas operaciones de entrada/salida requieren uso, y las operaciones de multiplicación y división con cifras grandes suponen al DX y al AX trabajando juntos.
◘ Registros Apuntadores: Los registros SP (apuntador de la pila) Y BP (apuntador de base) están asociados con el registro SS y permiten al sistema accesar datos en el segmento de la pila.
- Registro SP: El apuntador de la pila de 16 bits esta asociado con el registro SS y proporciona un valor de desplazamiento que se refiere a la palabra actual que esta siendo procesada en la pila. Los procesadores 80386 y posteriores tienen un apuntador de pila de 32 bits, el registro ESP. El sistema maneja de forma automática estos registros.
- Registro BP: El BP de 16 bits facilita la referencia de parámetros, los cuales son datos y direcciones transmitidos vía pila. Los procesadores 80386 y posteriores tienen un BP ampliado de 32 bits llamado el registro EBP.
◘ Registros Indice: Los registros SI y DI están disponibles para direccionamiento indexado y para sumas y restas.
- Registro SI: El registro índice fuente de 16 bits es requerido por algunas operaciones con cadenas (de caracteres). En este contexto, el SI esta asociado con el registro DS. Los procesadores 80386 y posteriores permiten el uso de un registro ampliado de 32 bits, el ESI.
- Registro DI: El registro índice destino también es requerido por algunas operaciones con cadenas de caracteres. En este contexto, el DI esta asociado con el registro ES. Los procesadores 80386 y posteriores permiten el uso de un registro ampliado de 32 bits, el EDI.
◘Registro de Banderas: De los 16 bits del registro de banderas, nueve son comunes a toda la familia de procesadores 8086, y sirven para indicar el estado actual de la maquina y el resultado del procesamiento. Muchas instrucciones que piden comparaciones y aritmética cambian el estado de las banderas, algunas cuyas instrucciones pueden realizar pruebas para determinar la acción subsecuente. En resumen, los bits de las banderas comunes son como sigue:
- OF (Overflow, desbordamiento): Indica desbordamiento de un bit de orden alto (mas a la izquierda) después de una operación aritmética.
- DF (dirección): Designa la dirección hacia la izquierda o hacia la derecha para mover o comparar cadenas de caracteres.
- IF (interrupción): Indica que una interrupción externa, como la entrada desde el teclado, sea procesada o ignorada.
- TF (trampa): Permite la operación del procesador en modo de un paso. Los programas depuradores, como el DEBUG, activan esta bandera de manera que usted pueda avanzar en la ejecución de una sola instrucción a un tiempo, para examinar el efecto de esa instrucción sobre los registros de memoria.
- SF (signo): Contiene el signo resultante de una operación aritmética (0 = positivo y 1 = negativo).
- ZF (cero): Indica el resultado de una operación aritmética o de comparación (0 = resultado diferente de cero y 1 = resultado igual a cero).
- AF (acarreo auxiliar): Contiene un acarreo externo del bit 3 en un dato de 8 bits para aritmética especializada.
- PF (paridad): Indica paridad par o impar de una operación en datos de 8 bits de bajo orden (mas a la derecha).
- CF (acarreo): Contiene el acarreo de orden mas alto (mas a la izquierda) después de una operación aritmética; también lleva el contenido del ultimo bit en una operación de corrimiento o de rotación.
Las banderas mas importantes para la programación en ensamblador son O, S, Z y C, para operaciones de comparación y aritméticas, y D para operaciones de cadenas de caracteres. Los procesadores 80286 y posteriores tienen algunas banderas usadas para propósitos internos, en especial las que afectan al modo protegido. Los procesadores 80286 y posteriores tienen un registro extendido de banderas conocido como Eflags.
- ◘ Registros de PILA: La pila es un área de memoria importante y por ello tiene, en vez de uno, dos registros que se usan como desplazamiento (offset) para apuntar a su contenido. Se usan como complemento al registro y son:
- SP (Stack Pointer): Se traduce como puntero de pila y es el que se reserva el procesador para uso propio en instrucciones de manipulado de pila. Por lo general, el programador no debe alterar su contenido.
- BP (Base pointer): Se usa como registro auxiliar. El programador puede usarlo para su provecho.

1.3 La memoria principal (RAM)
La memoria principal o primaria, "Memoria Central ", es aquella memoria de un ordenador, donde se almacenan temporalmente tanto los datos como los programas que la CPU está procesando o va a procesar en un determinado momento. Por ejemplo, cuando la CPU tiene que ejecutar un programa, primero lo coloca en la memoria y después lo empieza a ejecutar.
Otros andarán más rápido si el sistema cuenta con más memoria RAM. La memoria Caché: dentro de la memoria RAM existe una clase de memoria denominada Memoria Caché que tiene la característica de ser más rápida que las otras, permitiendo que el intercambio de información entre el procesador y la memoria principal sea a mayor velocidad.
Está formada por bloques de circuitos integrados o chips capaces de almacenar, retener o "memorizar" información digital, es decir, valores binarios; a dichos bloques tiene acceso el microprocesador de la computadora. La MP se comunica con el microprocesador de la CPU mediante el bus de direcciones.
El ancho de este bus determina la capacidad que posea el microprocesador para el direccionamiento de direcciones en memoria. En algunas oportunidades suele llamarse "memoria interna" a la MP, porque a diferencia de los dispositivos de memoria secundaria, la MP no puede extraerse tan fácilmente por usuarios no técnicos.
La MP es el núcleo del sub-sistema de memoria de una computadora, y posee una menor capacidad de almacenamiento que la memoria secundaria, pero una velocidad millones de veces superior. Si tienes más memoria almacenas más datos.
Características de la Memoria
Las magnitudes importantes que caracterizan la Memoria Central o Principal son:
- Capacidad o tamaño de la misma. Es decir, el numero de miles de posiciones que contiene. Normalmente se expresan en K.palabras, aunque en los ordenadores personales al ser las palabras de 8 bits se expresan en K-bytes. En la actualidad, el tamaño de la palabra es múltiplo del byte, ya que de esta forma el acceso a la misma puede hacerse desde uno al ancho máximo del bus de datos, ahorrando en muchos casos tiempo. Así tendremos palabras de 8, 16, 32, 64 bits y capacidades de siempre medidas en potencia de dos: 8, 16, 64, 128 K...etc(siendo 1K igual a 1025).
- Tiempo de Acceso. Es el tiempo que invierte el ordenador desde que se emite la orden de lectura-escritura, hasta que finaliza la misma. Este tiempo es muy pequeño, y de el depende la potencia del ordenado. Son típicos tiempos del orden de microsegundos e incluso del orden de 2 a 10 nanosegundos.
- El tamaño de la celda define su anchura de palabra, y viene fijado por el ancho del registro de información de memoria. Si la palabra interna es superior a la de la memoria, necesitara hacer más de un acceso para conseguir toda la información.
1.4 El concepto de interrupciones
Definición: Una interrupción es el rompimiento en la secuencia de un programa para ejecutar un programa especial llamando una rutina de servicio cuya característica principal es que al finalizar regresa al punto donde se interrumpió el programa.
Dentro de una computadora existen dos clases de interrupciones:
◘ Interrupciones por software: Son aquellas programadas por el usuario, es decir, el usuario decide cuando y donde ejecutarlas, generalmente son usadas para realizar entrada y salida.
◘ Interrupciones por hardware: Son aquellas que son provocadas por dispositivos externos al procesador su característica principal es que no son programadas, esto es, pueden ocurrir en cualquier momento en el programa.
Existen dos clases de interrupciones de este tipo:
- Interrupciones por hardware enmascarables: Aquellas en las que el usuario decide si quiere o no ser interrumpido.
- Interrupciones por hardware no enmascarables (NMI): Aquellas que siempre interrumpen al programa.
Las interrupciones por software se ejecutan con ayuda de las instrucciones: INT e IRET, además se tiene 256 interrupciones: de la 00 a la FF.
Asociado al concepto de interrupción se tiene un área de memoria llamada vector de interrupciones; la cual contiene las direcciones de las rutinas de servicio de cada interrupción. Esta área se encuentra en el segmento 0000:0000.
Una interrupción es una situación especial que suspende la ejecución de un programa de modo que el sistema pueda realizar una acción para tratarla. Tal situación se da, por ejemplo, cuando un periférico requiere la atención del procesador para realizar una operación de E/S.
Las interrupciones constituyen quizá el mecanismo más importante para la conexión del microcontrolador con el mundo exterior, sincronizando la ejecución de programas con acontecimientos externos.
Pasos para el pricesamiento:
1.Terminar la ejecución de la instrucción máquina en curso.
2.Salva el valor de contador de programa, IP, en la pila, de manera que en la CPU, al terminar el proceso, pueda seguir ejecutando el programa a partir de la última instrucción.
3.La CPU salta a la dirección donde está almacenada la rutina de servicio de interrupción (ISR, Interrupt Service Routine) y ejecuta esa rutina que tiene como objetivo atender al dispositivo que generó la interrupción.
4. Una vez que la rutina de la interrupción termina, el procesador restaura el estado que había guardado en la pila en el paso 2 y retorna al programa que se estaba usando anteriormente.
Ejemplo de interrupciones:
int 01h-->un solo paso
int 02h-->interrupcion no enmascarable
int 03h--> punto de interrupcion
int 04h-->desbordamiento
int 05h-->impresion de pantalla
int 08h-->Cronometro
int 15h-->Servicios del sistema
int 16h-->Funciones de entrada del teclado
int 18h-->Entrada con el Basic de Rom
int 19h-->Cargador ed arranque
int 1Ah-->Leer y establecer la hora
int 1Bh-->Obtener el control con una interrupcion de teclado.
int 2oh-->Terminar un programa
int 33h->Funciones del Raton
1.5 Llamadas a servicios del sistema
Una llamada al sistema es un método o función que puede invocar un proceso para solicitar un cierto servicio al sistema operativo. Dado que, el acceso a ciertos recursos del sistema requieren la ejecución de código en modo privilegiado, el sistema operativo ofrece un conjunto de métodos o funciones que el programa puede emplear para acceder a dichos recursos. En otras palabras, el sistema operativo actúa como intermediario, ofreciendo una interfaz de programación (API) que el programa puede usar en cualquier momento para solicitar recursos gestionados por el sistema operativo.
Algunos ejemplos de llamadas al sistema son las siguientes:
- Time: que permite obtener la fecha y hora del sistema.
- Write: que se emplea para escribir un dato en un cierto dispositivo de salida, tales como una pantalla o un disco magnético.
- Read: que es usada para leer de un dispositivo de entrada, tales como un teclado o un disco magnético.
- Open: que es usada para obtener un descriptor de un fichero del sistema, ese fichero suele pasarse a write.
En los sistemas operativos bajo norma POSIX o similares, algunas llamadas al sistema muy usadas son: open, Read (system call), write, close, wait, exec, fork, exit y kill. Los sistemas operativos actuales tienen cientos de llamadas, por ejemplo, Linux 2.x y FreeBSD tienen más de 300.
Las llamadas al sistema comúnmente usan una instrucción especial de la CPU que causa que el procesador transfiera el control a un código privilegiado (generalmente es el núcleo), previamente especificado. Esto permite al código privilegiado especificar donde va a ser conectado, así como el estado del procesador.
Cuando una llamada al sistema es invocada, la ejecución del programa que invoca es interrumpida y sus datos son guardados, normalmente en su PCB (Bloque de Control de Proceso del inglés: Process Control Block), para poder continuar ejecutándose luego. El procesador entonces comienza a ejecutar las instrucciones de código de bajo nivel de privilegio, para realizar la tarea requerida. Cuando esta finaliza, se retorna al proceso original, y continúa su ejecución. El retorno al proceso demandante no obligatoriamente es inmediato, depende del tiempo de ejecución de la llamada al sistema y del algoritmo de planificación de CPU.
Generalmente, los sistemas operativos proveen bibliotecas que relacionan los programas de usuario y el resto del sistema operativo, usualmente una biblioteca C como glibc o el runtime de Microsoft C. Esta biblioteca maneja los detalles de bajo nivel para transferir información al kernel y conmutar a modo supervisor, así como cualquier procesamiento de datos o tareas que deba ser realizada en modo supervisor. Idealmente, esto reduce la dependencia entre el sistema operativo y la aplicación, e incrementa su portabilidad.
La implementación de las llamadas al sistema requiere un control de transferencia que involucra características específicas de la arquitectura del procesador. Una forma típica de implementar es usar una interrupción por software. Linux usa esta implementación en la arquitectura x86.
1.6 Modos de direccionamiento
Los modos de direccionamiento son las diferentes maneras de especificar un operando dentro de una instrucción en lenguaje ensamblador. Un modo de direccionamiento especifica la forma de calcular la dirección de memoria efectiva de un operando mediante el uso de la información contenida en registros y/o constantes, contenida dentro de una instrucción de la máquina o en otra parte.
Diferentes arquitecturas de computadores varían mucho en cuanto al número de modos de direccionamiento que ofrecen desde el hardware. Eliminar los modos de direccionamiento más complejos podría presentar una serie de beneficios, aunque podría requerir de instrucciones adicionales, e incluso de otro registro. Se ha comprobado que el diseño de CPUs segmentadas es mucho más fácil si los únicos modos de direccionamiento que proporcionan son simples.
La mayoría de las máquinas RISC disponen de apenas cinco modos de direccionamiento simple, mientras que otras máquinas CISC tales como el DEC VAX tienen más de una docena de modos de direccionamiento, algunos de ellos demasiado complejos. El mainframe IBM System/360 disponía únicamente de tres modos de direccionamiento; algunos más fueron añadidos posteriormente para el System/390.
Cuando existen solo unos cuantos modos, estos van codificados directamente dentro de la propia instrucción (Un ejemplo lo podemos encontrar en el IBM/390, y en la mayoría de los RISC). Sin embargo, cuando hay demasiados modos, a menudo suele reservarse un campo específico en la propia instrucción, para especificar dicho modo de direccionamiento. El DEC VAX permitía múltiples operandos en memoria en la mayoría de sus instrucciones, y reservaba los primeros bits de cada operando para indicar el modo de direccionamiento de ese operando en particular.
Tipos de direccionamiento
◘ Implícito: En este modo de direccionamiento no es necesario poner ninguna dirección de forma explícita, ya que en el propio código de operación se conoce la dirección de el/los operando/s al (a los) que se desea acceder o con el/los que se quiere operar.
Supongamos una arquitectura de pila, las operaciones aritméticas no requieren direccionamiento explícito por lo que se ponen como: - add - sub ...Porque cuando se opera con dos datos en esta arquitectura se sabe que son los dos elementos del tope de la pila. Ejemplo de una pila
1 2 3 4 5 6 <- pila top() es 1 ntop() es 2
Donde top() representa el tope de la pila y ntop() el siguiente al tope de la pila y son estos argumentos con los que se opera al llamar a una orden en concreto.
◘ Inmediato: En la instrucción está incluido directamente el operando.
En este modo el operando es especificado en la instrucción misma. En otras palabras, una instrucción de modo inmediato tiene un campo de operando en vez de un campo de dirección. El campo del operando contiene el operando actual que se debe utilizar en conjunto con la operación especificada en la instrucción. Las instrucciones de modo inmediato son útiles para inicializar los registros en un valor constante.
Cuando el campo de dirección especifica un registro del procesador, la instrucción se dice que está en el modo de registro. Su valor es fijo, por lo que se suele utilizar en operaciones aritméticas o para definir constantes y variables. Como ventaja, no se requiere acceso adicional a memoria para obtener el dato, pero el tamaño del operando está limitado por el tamaño del campo de direccionamiento.
Las desventajas principales son que el valor del dato es constante y el rango de valores que se pueden representar está limitado por el tamaño de este operando.
◘ Directo: El campo de operando en la instrucción contiene la dirección en memoria donde se encuentra el operando.
En este modo la dirección efectiva es igual a la parte de dirección de la instrucción. El operando reside en la memoria y su dirección es dada directamente por el campo de dirección de la instrucción. En una instrucción de tipo ramificación el campo de dirección especifica la dirección de la rama actual.
Indirecto: El campo de operando contiene una dirección de memoria, en la que se encuentra la dirección efectiva del operando.
Si hace referencia a un registro de la máquina, la dirección de memoria (dirección efectiva) que contiene el dato estará en este registro y hablaremos de direccionamiento indirecto a registro; si hace referencia a una posición de memoria, la dirección de memoria (dirección efectiva) que contiene el dato estará almacenada en esta posición de memoria y hablaremos de direccionamiento indirecto a memoria.
La desventaja principal de este modo de direccionamiento es que necesita un acceso más a memoria que el directo. Es decir, un acceso a memoria para el direccionamiento indirecto a registro y dos accesos a memoria para el direccionamiento indirecto a memoria; por este motivo este segundo modo de direccionamiento no se implementa en la mayoría de las máquinas

◘ Absoluto: El campo de operando contiene una dirección en memoria, en la que se encuentra la instrucción. Y no se cancela.
◘ De registro: Sirve para especificar operandos que están en registros. En este modo, los operandos están en registros que residen dentro de la CPU.

◘ Indirecto mediante registros: El campo de operando de la instrucción contiene un identificador de registro en el que se encuentra la dirección efectiva del operando.
En este modo el campo de la dirección de la instrucción da la dirección en donde la dirección efectiva se almacena en la memoria. El control localiza la instrucción de la memoria y utiliza su parte de dirección para acceder a la memoria de nuevo para leer una dirección efectiva. Unos pocos modos de direccionamiento requieren que el campo de dirección de la instrucción sea sumado al control de un registro especificado en el procesador. La dirección efectiva en este modo se obtiene del siguiente cálculo:
Dir. efectiva = Dir. de la parte de la instrucción + Contenido del registro del procesador.
◘ De desplazamiento: Combina el modo directo e indirecto mediante registros.
◘ De pila: Se utiliza cuando el operando está en memoria y en la cabecera de la pila.
Este direccionamiento se basa en las estructuras denominadas Pila (tipo LIFO), las cuales están marcados por el fondo de la pila y el puntero de pila (*SP). El puntero de pila apunta a la última posición ocupada. Así, como puntero de direccionamiento usaremos el SP.
El desplazamiento más el valor del SP nos dará la dirección del objeto al que queramos hacer referencia. En ocasiones, si no existe C. de desplazamiento solo se trabajara con la cima de la pila. Como es un modo de direccionamiento implícito, solo se utiliza en instrucciones determinadas, las más habituales de las cuales son PUSH (poner un elemento en la pila) y POP (sacar un elemento de la pila).
Este tipo de direccionamiento nos aporta flexibilidad pero por el contrario, es mucho más complejo que otros tipos estudiados más arriba.
◘ Relativo a un registro base: Consiste, al igual que el indirecto a través de registro, en calcular la dirección efectiva (EA, effective address) como la suma del contenido del registro base y un cierto desplazamiento (offset) que siempre será positivo. Esta técnica permite códigos reentrantes y acceder de forma fácil y rápida a posiciones cercanas de memoria.
Este modo de direccionamiento es muy usado por los ensambladores cuando se llaman a las funciones (para acceder a los parámetros almacenados en la pila).
◘ Relativo a un registro índice: Es similar al direccionamiento relativo a un registro base, excepto que es el contenido del registro índice el que indica el desplazamiento que se produce a partir de una dirección de memoria que se pasa también como argumento a la orden que utiliza este modo de direccionamiento. Aunque en esencia son dos modos equivalentes. La EA se calcula como la suma del contenido del registro índice y una dirección de memoria.
◘ Indexado respecto a una base: Se trata de una combinación de los dos anteriores y consiste en calcular la dirección efectiva como:
- Relativo al contador de programa: Consiste en dirección una posición de memoria usando como registro base al contador de programa (PC), el funcionamiento es análogo al direccionamiento respecto a registro base con la salvedad de que, en este caso, el offset puede ser también negativo.
- Indexado con autoincremento/autodecremento: Es un modo de direccionamiento análogo al indexado, explicado anteriormente.
La única diferencia es que permite un incremento o decremento de la dirección final o el registro índice según los siguientes casos:
- Indexado con autopreincremento: Incrementa el registro índice primero (se incrementa un valor, según el tamaño del objeto direccionado) y luego calcula la EA al igual que el direccionamiento indexado.
- Indexado con autoposincremento: Calcula la dirección efectiva y después incrementa esta.
- Indexado con autopredecremento: Decrementa el registro índice y después calcula la dirección efectiva.
- Indexado con autoposdecremento: Calcula la dirección efectiva y después decrementa esta.
◘ Instrucción de salto con direccionamiento absoluto: Consiste en cargar en el PC el valor que se especifica, por ¿ejemplo: jmp 0xAB ----> Carga 0xAB en PC.
◘ Instrucción de salto con direccionamiento relativo: Es parecida a la especificada anteriormente la diferencia es que el salto es relativo al PC.
Ejemplo: supongamos que PC vale = 0x0A, si nosotros interpretamos la instrucción jr +03, saltaremos tres posiciones posteriores a PC (también podría ser -03 y serían posiciones anteriores). Pero, ¡cuidado! si esa instrucción estaba en la posición 0x0A la dirección de PC a incrementar será la inmediatamente posterior (ya que PC se incrementa automáticamente después de leer la instrucción), por lo que quedaría:
PC = 0x0B ---> nuevo PC = 0x0B+0x03 = 0x0E, con lo que el PC quedaría como 0x0E.
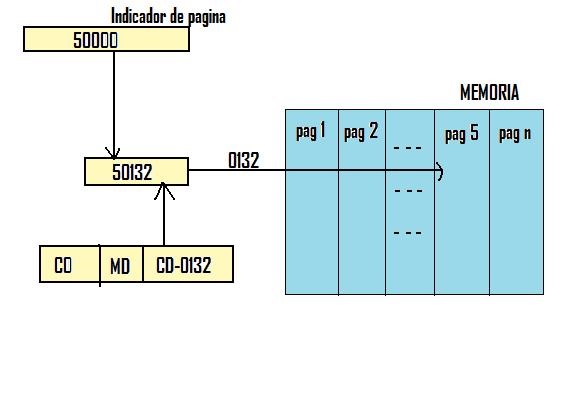
◘ Direccionamiento paginado: En el paginado la memoria se encuentra actualmente dividida en páginas (bloques de igual longitud). Para obtener las direcciones se necesita:
- Indicador de página (IP): en un registro específico o de propósito general de la máquina.
- Dirección de la palabra (DP):
en el campo CD de la instrucción.
Así, concatenando ambas partes se obtiene la dirección completa.

El problema viene cuando queremos referenciar un dato al que no podemos acceder de forma relativa (p.e. porque los registros base no puedan alcanzar dicha posición aun con el direccionamiento absoluto. Sin embargo, sólo una pequeña parte de la memoria se puede acceder (64 kilobytes, si el desplazamiento es de 16 bits).
El desplazamiento de 16 bits puede parecer muy pequeño en relación con el tamaño de la memoria de los equipos actuales (esta es la razón por la 80386 se expandió a 32 bits). Podría ser peor ya que: los sevidores IBM System/360 sólo tienen un signo de 12 bits de desplazamiento. Sin embargo, el principio de localización se aplica en un corto espacio de tiempo, la mayoría de los elementos de datos que un programa quiere acceder están bastante cerca uno del otro.
Este modo de direccionamiento está estrechamente relacionado con el modo de direccionamiento absoluto.
Ejemplo 1: Dentro de una subrutina, un programador estará principalmente interesados en los parámetros y las variables en los atributos del objeto actual.
1.7 Proceso de ensamblado y ligado
Pasos para llevar a cabo el proceso:
1. El programa utiliza un editor de texto para crear un archivo de texto ASCII, conocido como archivo de código fuente.
2. El ensamblador lee el archivo de código fuente y produce un archivo de código objeto, una traducción del programa a lenguaje máquina. De manera opcional, produce un archivo de listado. Si ocurre un error, el programador debe regresar al paso 1 y corregir el programa.
3. El enlazador lee el archivo de código objeto y verifica si el programa contiene alguna llamada a los procedimientos en una biblioteca de enlace. El enlazador copia cualquier procedimiento requerido de la biblioteca de enlace, lo combina con el archivo de código objeto y produce el archivo ejecutable. De manera opcional, el enlazador puede producir un archivo de mapa.
4. La herramienta cargador (loader) del sistema operativo lee el archivo ejecutable y lo carga en memoria, y bifurca la CPU hacia la dirección inicial del programa, para que éste empiece a ejecutarse.
1.8 Desplegado de mensajes en el monitor
Para poder desplegar los mensajes en lenguaje ensamblador es preciso conocer primero la estructura del lenguaje ensamblador, la cual es:
◘ Palabras reservadas:
- PAGE: designa el número máximo de líneas para listar en una página y el número máximo de caracteres en una línea.
- TITLE: para hacer que un título en un programa se imprima en la línea 2 de cada página en el listado del programa.
- SEGMENTS Y ENDS
- ASSUME
◘ Identificadores: nombre que se le da a algunos elementos del programa.
◘ Operación.
◘ Operando.
Todos los gráficos y el texto que se muestran en el monitor se escriben en la RAM de visualización de video, para después enviarlos al monitor mediante el controlador de video. El controlador de video es en sí un microprocesador de propósito especial, que libera a la CPU principal del trabajo de controlar el hardware de video.
Un monitor de pantalla de cristal líquido (LCD) digital directo recibe un flujo de bits digitales directamente desde el controlador de video, y no requiere del barrido de trama.